dogriley
liked this activity

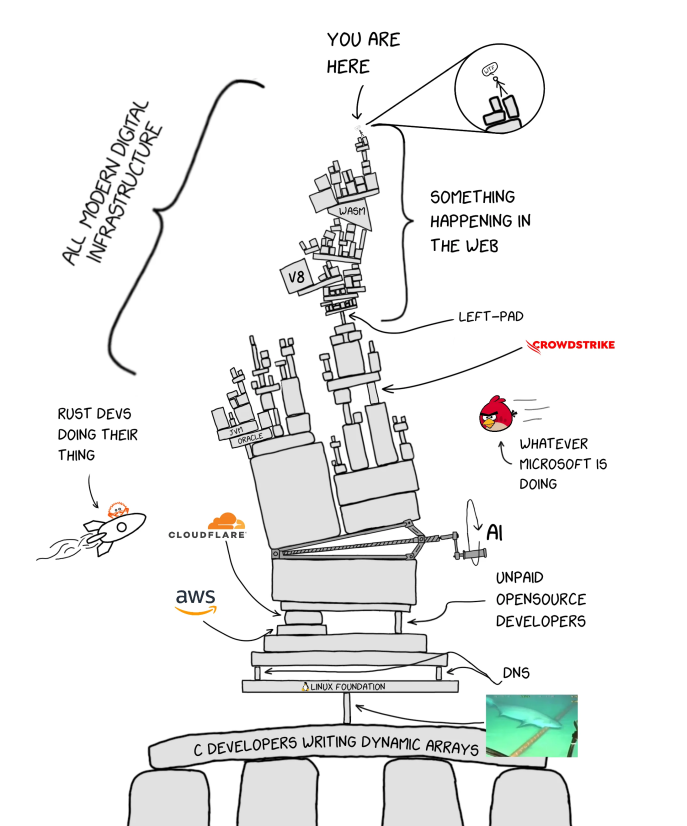
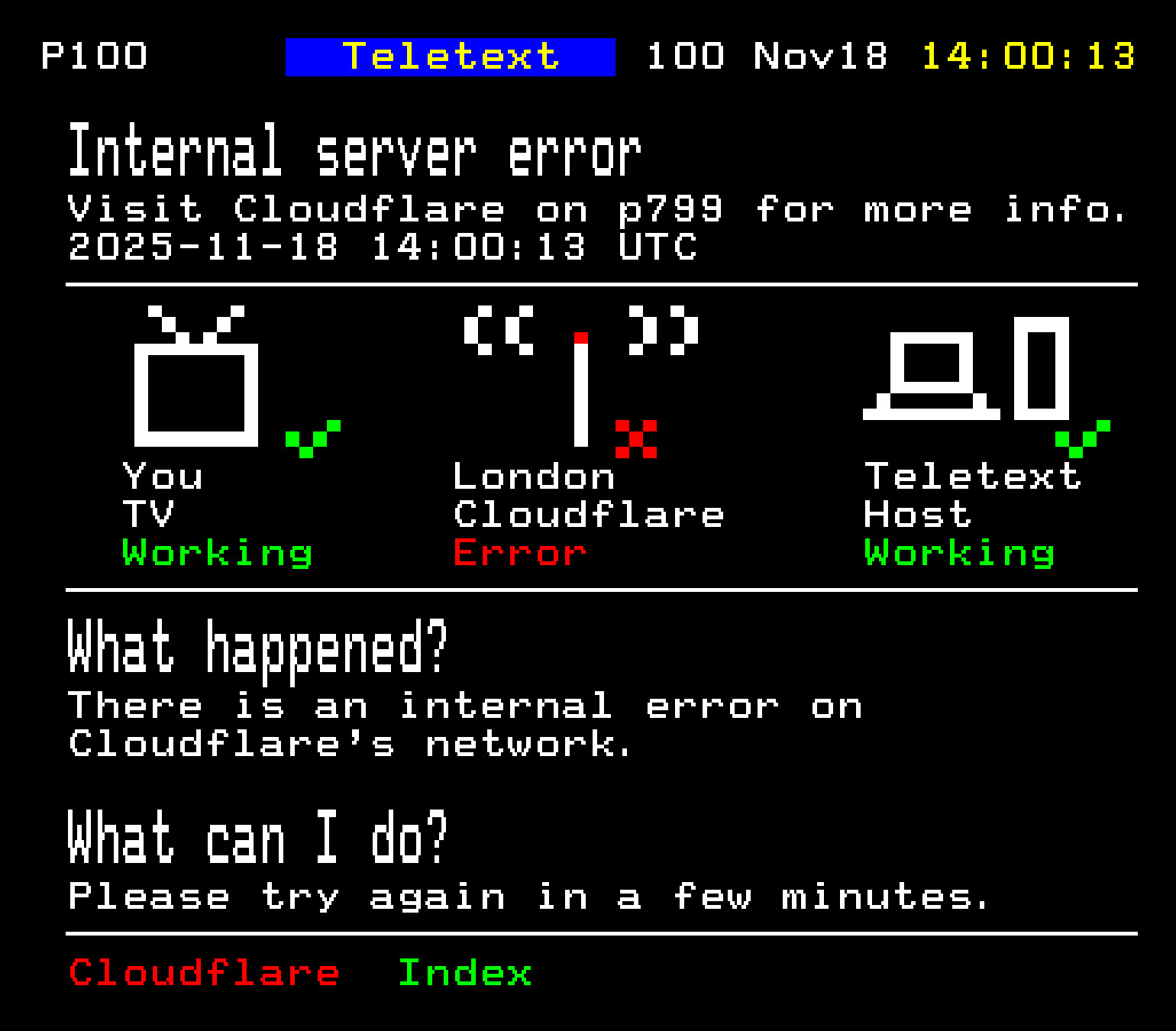
I haven't seen this variation of XKCD 2347 yet. Received from a friend, source unknown.